When a program needs to run faster by using more CPU cores, it is quite common to start with the parallelization of for loops. In this case, the execution of the loop is separated to multiple threads, each working on a part of the original loop. If for example an array with 24 elements needs to get processed and 12 system cores are available, each thread could process two consecutive elements (first thread 1 and 2, second thread 3 and for and so on). Of course, other constellations are also possible. For this purpose, it is common to have a parallel_for loop in a multithreading library (e.g. in Intel®'s TBB library). I wrote my own version just using C++11, which I want to introduce in this article. First I start with some basic (personal) requirements for such a function and then show some working code (tl;dr view the source directly on GitHub).
Whenever I needed to parallelize some loop, the basic problem is quite similar: I have some data structure containing some elements. Each element needs to get (expensively) processed and the result stored in a shared variable. For example, a list of images where each image is processed individually producing some feature data as output. All outputs are stored in the same variable. It might also be useful to output some status information to the console during execution. This makes it necessary to a) schedule the execution to multiple threads and b) make sure that the threads don't interfere when storing the results to the shared variable or writing something to the console. The situation is also illustrated in the following figure.
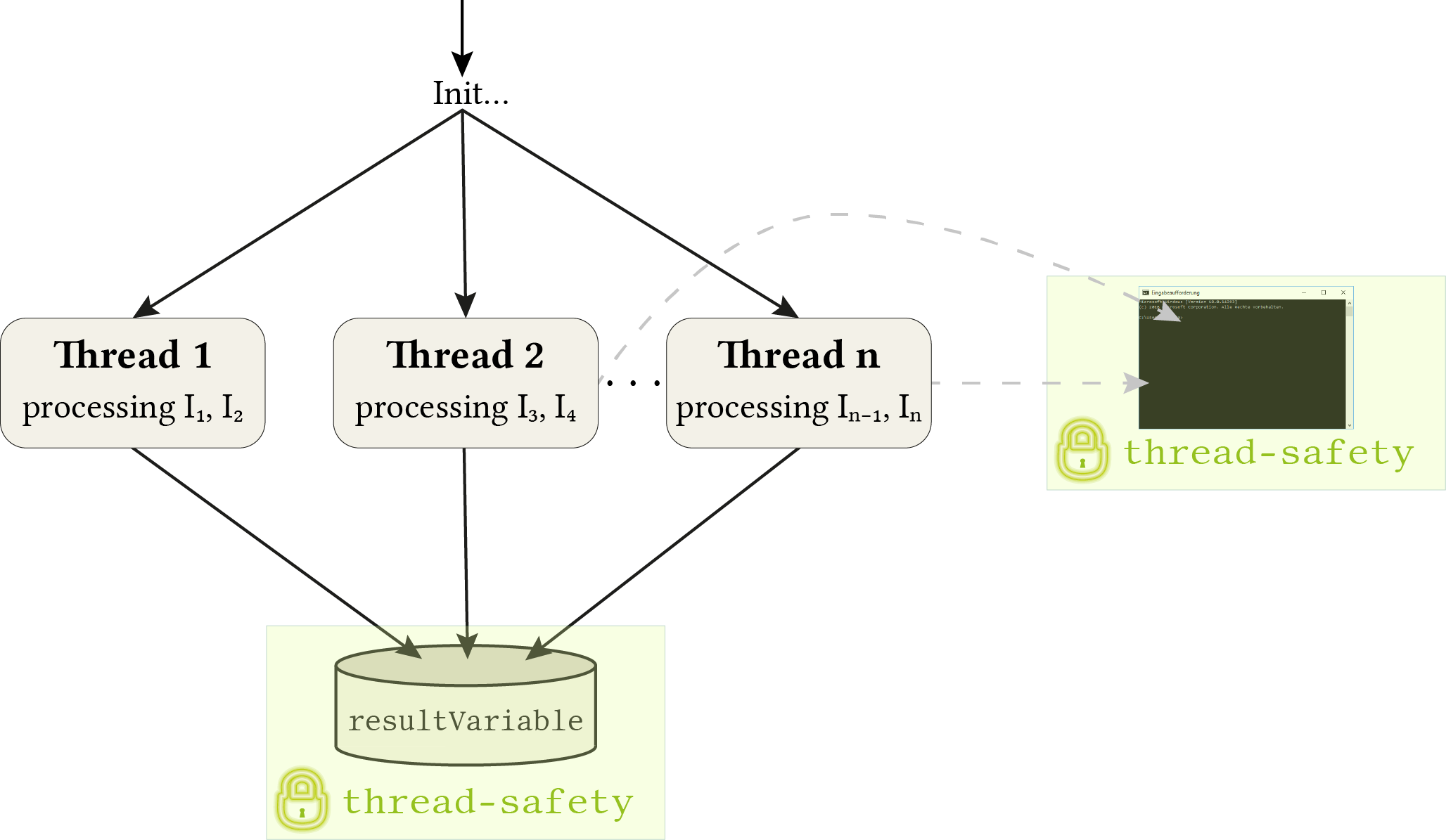
As the figure suggests, special care is necessary at two points: storing the result and print something to the console. It is assumed that the processing task itself is already thread-safe (it can be unproblematically executed multiple times from within several threads at the same time interval). Of course, this comes not for free and may need special treatment. But this should not be of interest at the current abstraction level.
To ensure the thread-safety a std::mutex is used together with a std::lock_guard. A mutex is a way of concurrency control to ensure controlled behaviour over critical parts of the code1. For example, if it should be ensured that a function will only be executed from one thread at the same time because the code inside the function writes to some variable and if multiple threads would do this at the same time, it would get messy. A mutex helps with this kind of scenarios. Whenever a thread A enters the function it locks the mutex. If the mutex is free (no other thread locked before), the current thread takes control over the mutex. If now an additional thread B enters the same function while thread B still processes it and tries also to lock it, then thread B has to wait until thread A is ready. The “readiness” is signalled through an unlock of the mutex at the end of the function. The unlocking also invokes a signal process which informs thread B that it can now proceed further. The used lock-guard ensures this procedure of lock and unlock automatically, by locking the mutex inside the constructor and unlocking it inside the destructor (the great RAII concept). The lock-guard object is created at the beginning of the function on the stack.
In its heart, there is the parallel_for() function which replaces the standard for-loop. The idea is to give this function a range of indices which need to get processed and the functions divides this range into several parts and assigns each thread one part (like the situation illustrated in the figure where indices 3 and 4 get assigned to Thread 2). Then all threads are started each processing the elements corresponding to their assigned indices.
This all said, it is now time for some code. I will only cover the client usage side. The (documented) class together with a test project is available on GitHub. The class is named ParallelExecution and offers three basic methods, which are all covered in the following example (from the test program). The only constructor parameter is the number of threads to use (if not otherwise explicitly specified). If omitted, it defaults to the number of available system cores (virtual + real).
std::deque<double> parallelExecution(const std::deque<double>& inputA, const std::deque<double>& inputB)
{
/* Note: the code is just an example of the usage of the ParallelExecution class and does not really cover a useful scenario */
assert(inputA.size() == inputB.size() && "Both input arrays need to have the same size");
ParallelExecution pe(12); // Number of threads to use, if not otherwise specified
std::deque<double> result(inputA.size(), 0.0);
pe.parallel_for(0, iterations - 1, [&](const size_t i) // Outer for loop uses as much threads as cores are available on the system
{
pe.parallel_for(0, result.size() - 1, [&](const size_t j) // Inner for loop uses 2 threads explicitly (the parallelization at this point does not really make sense, just for demonstration purposes)
{
const double newValue = (inputA[j] + inputB[j]) / (i + j + 1);
pe.setResult([&] ()
{
result[j] += newValue; // Store the result value in a thread-safe way (in different iterations the same variable may be accessed at the same time)
});
}, 2);
pe.write("Iteration " + std::to_string(i) + " done"); // Gives a threads-safe console output
});
return result;
}
There are basically 3 methods which cover the so fare discussed points:
parallel_for(idxBegin, idxEnd, callback, numbThreadsFor [optional]): this is the most important methods since it replaces the otherwise usedfor (int i = 0; i < input.size(); i++)loop. It gets the range of consecutive indices and a callback function. This function will be called from each thread for each assigned index (parameteri). To stick with the example from the figure, Thread 2 would call the callback two times, once with the parameter 3 and once with 4. Last but not least, it is possible to specify the number of threads which should be used for the current loop as an optional parameter. If omitted, the number given in the constructor will be used.setResult(callback): covers the bottom part of the figure. After the data is calculated it should be stored in the shared result variable by ensuring thread-safety (internally done by using a mutex).write(message): covers the right part of the figure to output to the console in a thread-safe way, so that different messages from different threads don't interfere. Internally, this is also done by using a mutex. It is a different one compared to the one used forsetResult()though since it is no problem when one thread accesses the result variable and another thread writes to the console window at the same time (non-interfering tasks).